What's New in Incorta Cloud 2023.7.0
Release Highlights
In the 2023.7.0 release, Incorta continues to enhance its platform and user experience by introducing multiple new features and significant enhancements.
- Schema managers can now create load plans with multiple schemas that can be executed in parallel or sequentially via load groups. To make load plans easier to manage, there is also a preview feature that shows the execution dependencies within a load group.
- Incorta Cloud platform now supports a multi-loader architecture where multiple loader services can manage data acquisition and ingestion in a cluster.
- Incorta has recently introduced dynamic fields. This feature enables dashboard developers to specify a range of measures, which dashboard viewers can then utilize to control the display of charts in the dashboard.
- Incorta has expanded its data delivery capabilities by including Google BigQuery and Microsoft Azure Synapse Analytics as data destinations. As a result, the integration between complex data sources and the new cloud data destinations is seamless.
- A new version of the Data Lineage Viewer now tracks and identifies both the upstream and downstream lineage of most system entities, including tables, views, variables, dashboards, and insights.
- Incorta continues to grow its native connector repository by adding three new data connectors.
- The 2023.7.0 release uses the Data Agent version 7.1.0. However, it may throw errors when running it on a Windows machine with the OpenJDK version 11.0.1.
- The 2023.7.1 and 2023.7.2 releases use the Data Agent version 7.1.2.
Please make sure to upgrade to the data agent version available on the Cloud Admin Portal.
Upgrade considerations
Metadata database check
Upgrading to 2023.7.x requires upgrading the metadata database to support multi-group load plans and migrate existing schema load jobs or load plans. Before upgrading to a 2023.7.x release, contact Incorta Support to perform a database check to inspect and detect any issues with your metadata database that might cause the metadata database upgrade to fail. If issues are detected, Incorta Support will run scripts against the metadata database to delete the records causing these issues.
If the records that should be deleted are related to a multi-schema scheduled load job, the scheduled load job will be deleted altogether, and you will need to recreate the load plan manually if required.
Public API v2
- Starting with 2023.7.0, all Incorta Public API v2 endpoints require defining the tenant’s name (case-sensitive) in the request URL.
- The response of the
/schema/{schemaName}/listendpoint has been updated. Some parameters have been renamed while additional parameters are now available to display error messages, the source column of runtime business view columns, and their data types. For more details, refer to Public API v2 → List Schema Objects.
Columns with Integer data type
In this release, Incorta can write columns with Integer data type as Integer (instead of Long) in Parquet files. Loading objects with Integer columns from source (full load) creates new Parquet files with Integer data and requires a full load for all their dependent objects. You can instruct the Loader Service to create new Parquet files and migrate these columns to Integer during loading from staging. For more details, see Maintaining Integer data during data loading.
New Features
- Multi-schema load plan enhancements
- Data lineage enhancements
- Dynamic fields applied in measures
- Expanded Data Delivery capabilities
- List of Values in presentation variables
- Null handling enhancements
- Announcements banner
- Hide prompts from the filter bar
- Grouping measure color palette for pie and donut visualizations
- Oracle Configure, Price, and Quote connector
- Oracle Transportation Management connector
- Autoline connector
- Multi-loader support
- Upload Components to Marketplace
- Limit downloading insights enhancement
- Maintaining Integer data during data loading
- Detecting duplicates during unique index calculations
- Enhanced logging framework
Multi-schema load plan enhancements
2023.7.0 introduces a lot of enhancements regarding the multi-schema load plans:
- Multi-schema load plan as a general availability (GA) feature
- Orchestrating load plans via sequential groups
- Visualizing the execution of load plans using Directed Acyclic Graphs (DAGs)
Multi-schema load plan: a general availability (GA) feature
The Multi-schema load plan introduced in 2022.11.0 as a preview feature is now a GA feature that is always enabled.
Orchestrating load plans via sequential groups
You can now organize schemas into load groups, simplifying the management of complex data applications that involve multiple schemas. Schemas can be loaded sequentially by ordering them by group. Within each group, schemas will load simultaneously (as resources allow), ensuring faster data refreshing cycles and maintaining dependencies between schemas

The Loader Service simultaneously loads all schemas in the first group, then starts loading the next group, and so on.

For more details, refer to Tools → Scheduler.
Visualizing the execution of load plans using DAGs
You can now preview the execution plan of each load plan visualized as a directed acyclic graph (DAG), which shows the load plan dependencies and order of execution.
To preview the DAG of a load plan:
- Select Scheduler > Load Plans.
- For the load plan you want, select Show DAG.
- Expand the nodes to show the included objects and processes.

The nodes represent the tasks or stages of the load plan while node order represents the dependency between objects. The DAG shows nodes for extraction, transformation (enrichment), PK-index creation, deduplication (compaction), locking, loading, and Post-Load calculations.
For more details, refer to Tools → Load Plan DAG Viewer.
Data lineage enhancements
A new version of the Data Lineage Viewer is now available as a preview feature. It displays an entity’s (column, variable, object…) upstream and downstream lineage. Upstream lineage lists the entities referenced in the current entity while downstream lineage lists entities where the current entity is referenced. The tool has an enhanced diagram that shows the hierarchy of dependencies where you can track upstream and downstream lineage.

In addition to tracking columns and formula columns, you can also track the lineage of other entities like:
- Physical schema tables

- Business runtime views

- Session and global variables
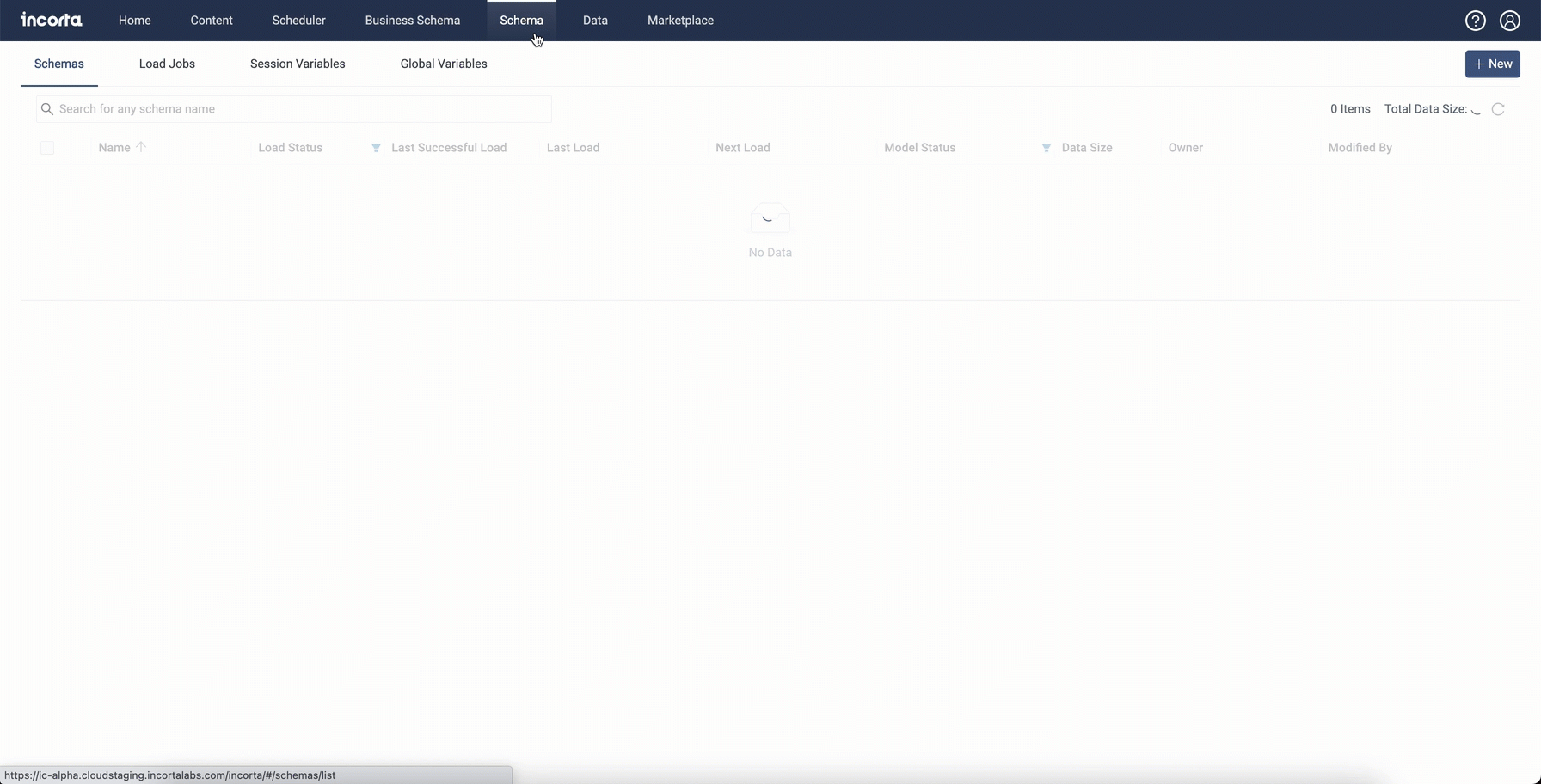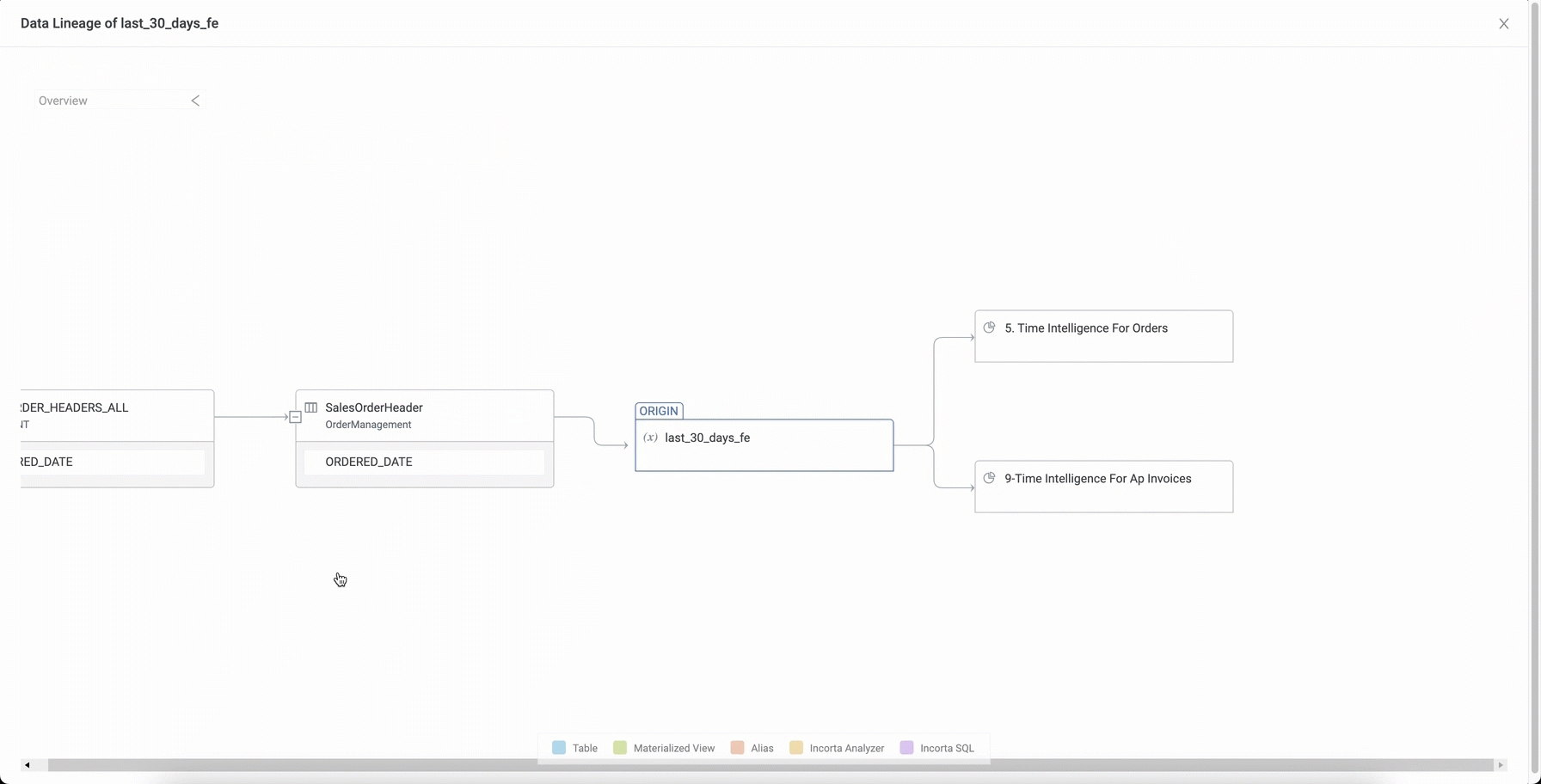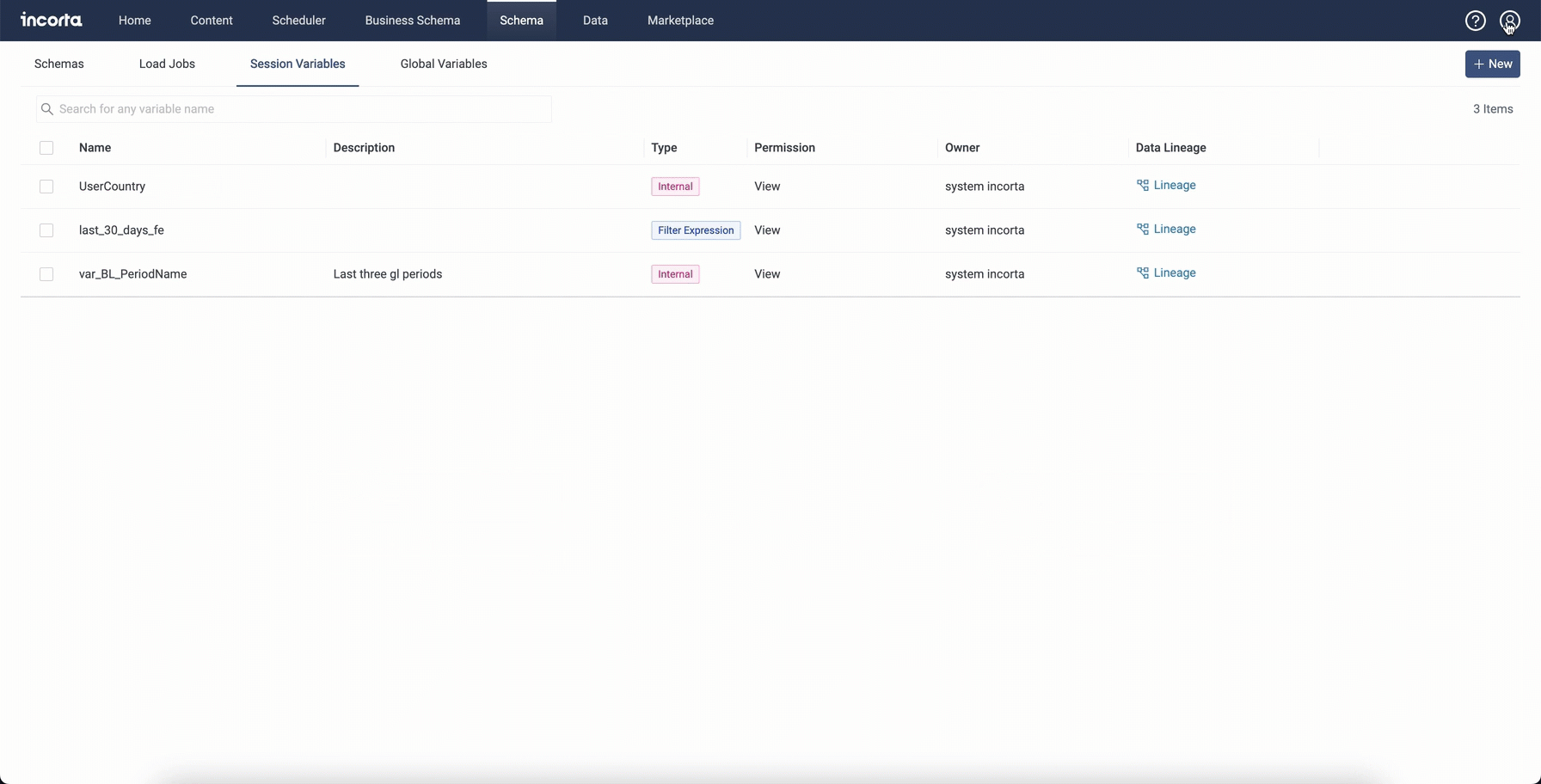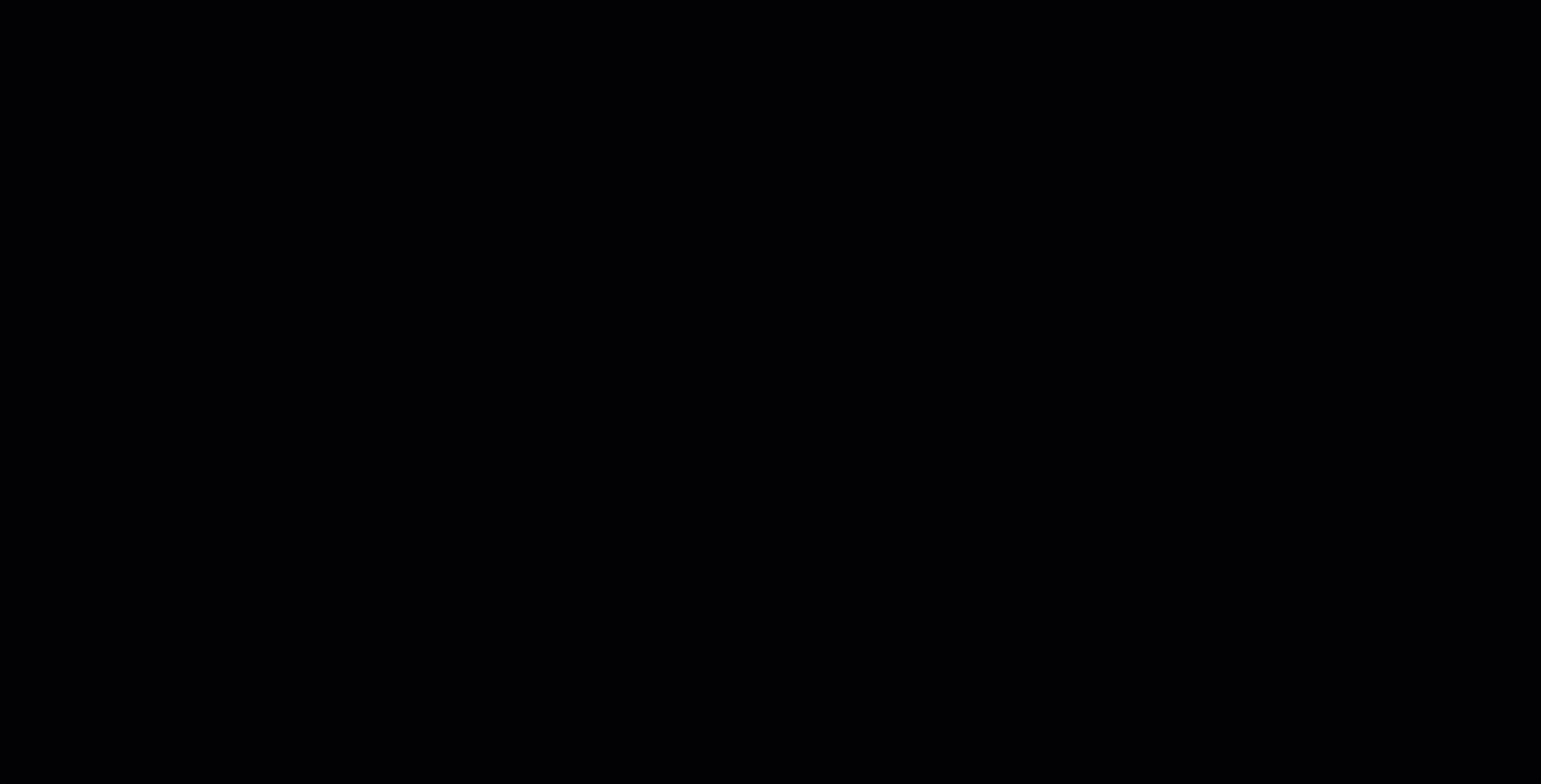
- Dashboards and insights

Incorta has also improved the accessibility of data lineage in the platform. You can now:
- Quickly identify lineage object types through improved color-coding and icon-coding.
- Access dashboards from within the lineage diagram.
For more details, refer to Tools → Data Lineage Viewer v2.
Dynamic fields
A dynamic field is a group of dynamically interchangeable fields. The analyze user, building insights and dashboards, would add multiple measures to a dynamic field from the Manage Dashboard Filters within the dashboard scope. The analyze user can then add the dynamic field to the measure tray for any insight created within the same dashboard scope. The dashboard viewer would dynamically switch between the different measures of the dynamic field.
Note: This feature is only available in interactive dashboards. Currently, sending and downloading a dashboard as PDF respects the selected dynamic field.

For more information, refer to Concepts → Dynamic field and Tools → Dashboard Filters Manager.
Expanded Data Delivery Capabilities
In this release, Incorta introduces Google BigQuery and Microsoft Azure Synapse Analytics destinations for data delivery. With data destinations, Incorta will not only ingest and enrich data, but also push full and incremental loads of data to another cloud analytics platform. The new data delivery capabilities streamline the integration between complex data sources and Microsoft Azure Synapse Analytics and Google BigQuery. It also accelerates data mart deployment and automates data model design and source schema mapping with Incorta data applications. For more information, refer to the Incorta Data Delivery configuration documents.

List of Values in presentation variables
Presentation variables now accept a user-defined list of values. This feature lets you easily filter data based on manual user input at runtime instead of pre-existing data columns.
When you create a presentation variable, you can choose to manually enter a set of defined values as the source of your presentation variable. The set of values can be a comma or line-separated list entered into the bulk edit of the filter values. Make sure to always select the default value.

For more information, refer to Concepts → Presentation variable.
Null handling enhancements
Sorting and filtering data based on physical columns now account for null values.
- When sorting data in an insight, Analyzer table, or Analyzer view in ascending order, null values will be first.
- Filters respect null values when applying filters to insights, dashboards, Analyzer tables, or Analyzer views.
Sorting and filtering based on formula columns do not account for null values for now.
Sorting based on a physical table column from a joined table does not account for null values in the sorting column when the joined columns do not include null values. Consequently, the original column is not sorted as expected.
Announcements banner
Incorta can now broadcast announcements via an announcement banner to users within the Incorta platform. The banner announcement can now be set up and sent out through the CMC using the Notifications feature found in the Server Configurations section. This can be done by either the CMC cloud admin or the CMC admin.

The banner will display to all tenant users. When users dismiss the notification banner, it will only appear to them again once the admin creates a new announcement.

For more information on how to configure the notifications, refer to Guides → Configure Server.
Hide prompts from the filter bar
This release introduces a new option that will hide prompts from the dashboard filter bar. The Hide from filter bar option is now available for prompts. This option can be enabled while setting up the prompt in the Dashboard Filters Manager.
Incorta will apply the prompt to your dashboard regardless of enabling this option.
Note: The Clear All option clears all shown and hidden prompts.

For more information refer to Concepts → Prompts and Tools → Dashboard Filters Manager.
Grouping measure color palette for pie and donut visualizations
Additional configurations are available to control the colors of donut and pie charts to align them with dashboard themes. The Format Color Palette option is now available for grouping dimensions in pie and donut visualizations.

Oracle Configure, Price, and Quote connector
With the addition of the Oracle CPQ REST API connector, Incorta now allows you to connect to your Oracle CPQ system seamlessly. By utilizing this connector, you can collect valuable data and gain meaningful insights that will help you optimize your opportunity-to-quote-to-order process.
This connector is available for preview only.

For more information, refer to Connectors → Oracle CPQ.
Oracle Transportation and Global Trade Management connector
With Incorta, you can now easily connect to your Oracle CPQ system using the Oracle OTM/GTM connector, which is based on REST APIs. This connector allows you to collect data on all your transportation activities across your global supply chain and trading.
This connector only supports Oracle OTM/GTM version 23A and is available for preview.

For more information, refer to Connectors → Oracle OTM/GTM.
Autoline connector
With the new Autoline connector, you can easily access your Autoline suite and directly query your data. This connector uses the cdata.jdbc.jdbcodbc.jar driver to establish a seamless connection to Autoline.
The Incorta Autoline connector is available for preview only.

For more information, refer to Connectors → Autoline.
Multi-loader support
The Incorta Cloud system can now support a multi-loader architecture, which allows multiple Loader Services to manage the acquisition and ingestion of data within the same cluster. This setup ensures that all loader services have access to the same schema model and file versions, maintaining consistency throughout the process. To determine which loader service should execute a load job, Zookeeper considers various factors, such as the number of running load jobs and the maximum number of concurrent load jobs a loader service can handle simultaneously.
This architecture doesn’t support schema distribution for multi-schema load jobs. Therefore, avoiding schema distribution is important if you are utilizing multi-schema load jobs and vice versa.
Upload Components to Marketplace
In this release, Incorta enables uploading custom-developed components to the external components list.
- Log in to Incorta.
- Navigate to Content.
- Create a new dashboard or use an existing one.
- Select Edit.
- In the Add Insight pane, scroll to External Component, and then select Add Component.
- In the Components screen, select Upload.
- Drag and drop your .inc file.

For more information, refer to the Component SDK documentation.
Limit downloading insights enhancement
In this release, Incorta renamed the Users with “User” or “Individual Analyzer” roles can download insights option previously introduced in 2023.4.1 to be “Download insights”. Disable this option to prevent users with “User” or “Individual Analyzer” roles from downloading insights. The option is now available for configuration by the CMC cloud admin and CMC cloud admin.

Maintaining Integer data during data loading
In previous releases, Incorta wrote Integer columns in Parquet as Long. However, starting with 2023.7.0, Incorta writes Integer columns in Parquet as Integer for all newly created tables. For previously created tables, Incorta converts Integer columns written as Long in Parquet files to Integer during full load jobs, while Incorta keeps these columns unchanged during incremental loads.
As a result, after performing a full load of a table with Integer columns, it is recommended that you perform a full load of its dependent schema objects to ensure data consistency.
To migrate all Parquet files to have Integer data without fully loading your objects, the administrator can turn on the Enable Parquet Migration at Staging option in the Cluster Management Console (CMC) > Server Configurations > Tuning and perform a load from staging for all your objects with Integer columns.

- Turning the Enable Parquet Migration at Staging option on adds a new step that runs on Spark to the staging load jobs. Ensure Spark has sufficient resources to migrate the required Parquet files.
- The migration of Parquet files during staging load occurs only once per object.
- Load tables before loading MVs that read from these tables.
- When loading an object fully, you must load dependent objects or load all objects from staging after turning the Enable Parquet Migration at Staging option on.
- The new behavior might affect existing scripts referencing Integer or Long data, whether columns, values, or variables.
Detecting duplicates during unique index calculations
In previous releases, when the Enforce Primary Key Constraint option was disabled for physical tables or MVs, and the selected key columns resulted in duplicate key values, unique index calculations would not fail, the first matching value was returned whenever a single value of the key columns was required.
Starting with this release, in such a case, the unique index calculation will fail, and the load job will finish with errors. You must either select key columns that ensure row uniqueness and perform a full load or enable the Enforce Primary Key Constraint option and load tables from staging to have the unique index correctly calculated.
Enhanced logging framework
Incorta has made several improvements to its logging framework, including the handling of file naming, file size, and archiving. In this framework, a log file is automatically zipped to incorta-<date>-<file_number>.log.zip when it reaches 1GB or at the end of the day.
The following is an example for the logging process on February 3rd, 2023:
- Incorta started logging events in
incorta.logfile with the start of the day. - When the log file reached 1GB, Incorta zipped the current log file into
incorta-2023-02-03-01.log.zipfile. - Incorta recreated another
incorta.logfile to continue logging events for the same day. - By the end of the day, the second log file is zipped under the name:
incorta-2023-02-03-02.log.zip.
Incorta then retains the log files for a maximum of 6 months. To access older log files, please contact Incorta Support.
Existing log files created before the upgrade to this release will always exist.
Limit prompt filters dashboard selection
In this release, Incorta is enabling Cluster Management Console (CMC) admin to limit the number of selections in a dashboard prompt filter that a dashboard consumer can select to apply on a dashboard via a new configuration in the CMC. This limitation is applicable only for the following operators:
- In
- Not In
- Contains
- Does Not Contain
- Starts With
- Does Not Start With
- Ends With
You can find the new configuration in the CMC under Default Tenant Configuration > Incorta Labs > Max no. of selections for contains filter. The default value for the configuration is -1, which indicated an unlimited number of selections. 0 indicates an unlimited number of selections as well. Any number greater than 0 will indicate the maximum number of selections a dashboard consumer can select in a prompt filter.